
Metric server 설치
원래는 아래 github에서 CLI 한줄이면 설치가 가능하지만
이 글에서는 kind cluster로 학습하고 있기 때문에 설치가 불가능하다
https://github.com/kubernetes-sigs/metrics-server
전체파일로 설치하자
# metrics-server.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
- --kubelet-use-node-status-port
- --metric-resolution=15s
image: k8s.gcr.io/metrics-server/metrics-server:v0.6.2
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100아래 명령어를 적용해서 설치한 후 확인하고 진행하자
kubectl apply -f metrics-server.yaml
kubectl get pod -n kube-system
# 결과
NAME READY STATUS RESTARTS AGE
coredns-7c65d6cfc9-j7xg8 1/1 Running 0 2d17h
coredns-7c65d6cfc9-l76fn 1/1 Running 0 2d17h
etcd-dev-cluster-control-plane 1/1 Running 0 2d17h
kindnet-kqh8m 1/1 Running 0 2d17h
kindnet-rvdl9 1/1 Running 0 2d17h
kindnet-x9xlp 1/1 Running 0 2d17h
kube-apiserver-dev-cluster-control-plane 1/1 Running 0 2d17h
kube-controller-manager-dev-cluster-control-plane 1/1 Running 0 2d17h
kube-proxy-dpnls 1/1 Running 0 2d17h
kube-proxy-nsq78 1/1 Running 0 2d17h
kube-proxy-xk7vs 1/1 Running 0 2d17h
kube-scheduler-dev-cluster-control-plane 1/1 Running 0 2d17h
metrics-server-7b445dfdc-jhnv8 0/1 Running 0 29s # 이 부분이 1/1 이 되어야 한다.아래 명령어를 통해 memory와 cpu 사용량을 볼 수 있다.
# 파드 사용량 (현재는 pod가 없음)
kubectl top pod
# 결과
No resources found in default namespace.
# 노드에서의 사용량
kubectl top nodes
# 결과
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
dev-cluster-control-plane 206m 1% 848Mi 10%
dev-cluster-worker 28m 0% 265Mi 3%
dev-cluster-worker2 32m 0% 292Mi 3%리소스의 단위는 아래와 같다.
| Memory | 1M, 50M, 1G | 1Mi, 50Mi, 1Gi |
| CPU | 1 (하나의 CPU), 100m (CPU 1/10), 500m (CPU 1/5) (실제로는 이렇지 않지만 이렇게 생각해도 무방하다.) | |
만약 컨테이너가 memory나 cpu가 한도를 초과하면 어떻게 될까?
memory의 경우 kubelet이 컨테이너를 죽이고 재시작한다.
CPU의 경우 컨테이너가 죽지 않고 쓰로틀링이 걸린다. (성능이 저하될 수 있다.)
Pod pending
# 01-deploy-cpu-memory_usage.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deploy
spec:
selector:
matchLabels:
app: my-app
replicas: 3
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
cpu: 2
memory: 100Mi
limits:
cpu: 2
memory: 100Mi파일을 만들고 실행한 후 top으로 확인해보자
위의 파일에서 request 보다 더 많은 리소스를 사용할 수 있도록 허용하고
limit은 limit 보다 더 많은 리소스를 사용할 수는 없다.
kubectl apply -f 01-deploy-cpu-memory_usage.yaml
kubectl top pods
# 15초 간격으로 확인하기 때문에 pod를 실행하고 조금 기다린 후 다시 실행하자
error: metrics not available yet
kubectl top pods
# 결과
NAME CPU(cores) MEMORY(bytes)
my-deploy-6bcdc9d88f-chvvm 0m 15Mi
my-deploy-6bcdc9d88f-hwvw8 0m 15Mi
my-deploy-6bcdc9d88f-xsdh4 0m 15Mi아래 파일처럼 CPU 수를 늘리고 replicaSet도 늘려서 적용해보자
이 숫자는 worker CPU에 따라서 변경이 가능하다
아래 예시는 CPU가 부족할때를 보기 위함이다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deploy
spec:
selector:
matchLabels:
app: my-app
replicas: 5
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
cpu: 10
memory: 100Mi
limits:
cpu: 10
memory: 100Mi확인해보면 일부 pod가 pending 상태인걸 확인할 수 있다.
describe로 확인해보자
kubectl describe pod/my-deploy-6598fd5d9-q5frf
# 결과
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 111s (x4 over 2m1s) default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }, 2 Insufficient cpu. preemption: 0/3 nodes are available: 1 Preemption is not helpful for scheduling, 2 No preemption victims found for incoming pod.pod에 CPU를 할당해야하지만 모든 CPU가 사용중이라서 불가능하다.
해결방법은 실제로 노드를 늘리거나 pod를 줄이는 방법이다.
HPA template
2개의 파일을 만들자
# 02-deploy-for-hpa.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deploy
spec:
selector:
matchLabels:
app: my-app
replicas: 1
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx
startupProbe:
httpGet:
path: /
port: 80
periodSeconds: 1
failureThreshold: 30
readinessProbe:
httpGet:
path: /
port: 80
periodSeconds: 5
failureThreshold: 3
resources:
requests:
cpu: 50m
memory: 10Mi
limits:
cpu: 50m
memory: 10Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: my-app
ports:
- port: 80
targetPort: 80
---
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
spec:
terminationGracePeriodSeconds: 1
containers:
- name: demo
image: vinsdocker/util
args:
- "sleep"
- "3600"위의 파일은 deployment와 데모를 위한 pod 그리고 외부 접속을 위한 service이다.
nginx version에 따라서 cpu나 memory가 더 필요하면 pod가 켜지지 않을 수도 있다. 적당히 조절해주자
# 03-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deploy
minReplicas: 1
maxReplicas: 3
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 10
behavior:
scaleDown:
stabilizationWindowSeconds: 10이 파일은 deployment를 감시하며 autoscaling을 할 HPA 파일이다
이제 적용해보자
kubectl apply -f 02-deploy-for-hpa.yaml
kubectl apply -f 03-hpa.yaml이제 demo pod로 접속한 후 부하 테스트를 진행해서 pod가 auto scaling이 되는지 확인해보자
kubectl exec -it demo-pod -- bash
root@demo-pod:/# ab -n 20000 -c 5 http://nginx/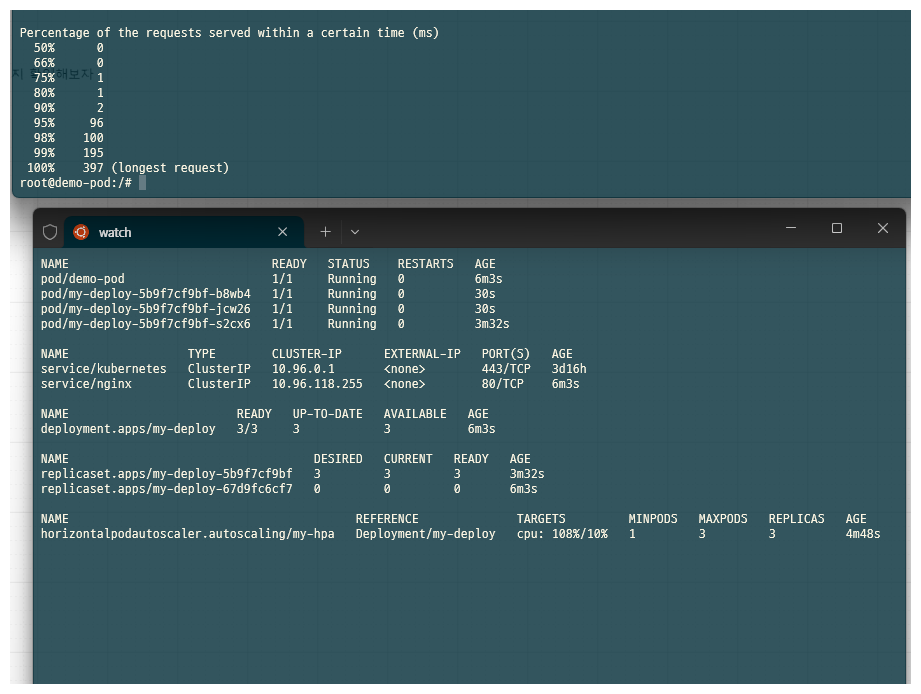
그러면 CPU가 더 사용됨에 따라 auto scaling이 되는것을 확인할 수 있다.
이 후 작업이 완료되면 다시 1개로 돌아온다
HPA - Without Probe
이전 2번에서 probe를 주석 처리 하자
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deploy
spec:
selector:
matchLabels:
app: my-app
replicas: 1
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx
# startupProbe:
# httpGet:
# path: /
# port: 80
# periodSeconds: 1
# failureThreshold: 30
# readinessProbe:
# httpGet:
# path: /
# port: 80
# periodSeconds: 5
# failureThreshold: 3
resources:
requests:
cpu: 50m
memory: 20Mi
limits:
cpu: 50m
memory: 20Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: my-app
ports:
- port: 80
targetPort: 80
---
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
spec:
terminationGracePeriodSeconds: 1
containers:
- name: demo
image: vinsdocker/util
args:
- "sleep"
- "3600"이제 적용해보자
kubectl apply -f 02-deploy-for-hpa.yaml
kubectl apply -f 03-hpa.yaml데모 파드로 접속한 후 요청을 보내보자
kubectl exec -it demo-pod -- bash
ab -n 20000 -c 5 http://nginx/중간에 connection이 거절당하는 것을 확인할 수 있다.
Benchmarking nginx (be patient)
Completed 2000 requests
Completed 4000 requests
Completed 6000 requests
Completed 8000 requests
Completed 10000 requests
Completed 12000 requests
apr_socket_recv: Connection refused (111)
Total of 12928 requests completed왜 이런일이 발생할까?
오토스케일링은 발생한다. 하지만 Probe가 있으면 컨테이너가 준비 된 후에 요청을 받지만
Probe가 없으면 컨테이너가 준비되기 전에도 요청을 받기 때문에 연결이 거부되는 상황이 생긴다.
'Kubernetes' 카테고리의 다른 글
| [Kubernetes] Ingress (0) | 2024.12.30 |
|---|---|
| [Kubernetes] Persistent Volume & StatefulSet (0) | 2024.12.30 |
| [Kubernetes] Secret (0) | 2024.12.19 |
| [Kubernetes] ConfigMap (0) | 2024.12.19 |
| [Kubernetes] Probes (0) | 2024.12.19 |
Metric server 설치
원래는 아래 github에서 CLI 한줄이면 설치가 가능하지만
이 글에서는 kind cluster로 학습하고 있기 때문에 설치가 불가능하다
https://github.com/kubernetes-sigs/metrics-server
전체파일로 설치하자
# metrics-server.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
- --kubelet-use-node-status-port
- --metric-resolution=15s
image: k8s.gcr.io/metrics-server/metrics-server:v0.6.2
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100아래 명령어를 적용해서 설치한 후 확인하고 진행하자
kubectl apply -f metrics-server.yaml
kubectl get pod -n kube-system
# 결과
NAME READY STATUS RESTARTS AGE
coredns-7c65d6cfc9-j7xg8 1/1 Running 0 2d17h
coredns-7c65d6cfc9-l76fn 1/1 Running 0 2d17h
etcd-dev-cluster-control-plane 1/1 Running 0 2d17h
kindnet-kqh8m 1/1 Running 0 2d17h
kindnet-rvdl9 1/1 Running 0 2d17h
kindnet-x9xlp 1/1 Running 0 2d17h
kube-apiserver-dev-cluster-control-plane 1/1 Running 0 2d17h
kube-controller-manager-dev-cluster-control-plane 1/1 Running 0 2d17h
kube-proxy-dpnls 1/1 Running 0 2d17h
kube-proxy-nsq78 1/1 Running 0 2d17h
kube-proxy-xk7vs 1/1 Running 0 2d17h
kube-scheduler-dev-cluster-control-plane 1/1 Running 0 2d17h
metrics-server-7b445dfdc-jhnv8 0/1 Running 0 29s # 이 부분이 1/1 이 되어야 한다.아래 명령어를 통해 memory와 cpu 사용량을 볼 수 있다.
# 파드 사용량 (현재는 pod가 없음)
kubectl top pod
# 결과
No resources found in default namespace.
# 노드에서의 사용량
kubectl top nodes
# 결과
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
dev-cluster-control-plane 206m 1% 848Mi 10%
dev-cluster-worker 28m 0% 265Mi 3%
dev-cluster-worker2 32m 0% 292Mi 3%리소스의 단위는 아래와 같다.
| Memory | 1M, 50M, 1G | 1Mi, 50Mi, 1Gi |
| CPU | 1 (하나의 CPU), 100m (CPU 1/10), 500m (CPU 1/5) (실제로는 이렇지 않지만 이렇게 생각해도 무방하다.) | |
만약 컨테이너가 memory나 cpu가 한도를 초과하면 어떻게 될까?
memory의 경우 kubelet이 컨테이너를 죽이고 재시작한다.
CPU의 경우 컨테이너가 죽지 않고 쓰로틀링이 걸린다. (성능이 저하될 수 있다.)
Pod pending
# 01-deploy-cpu-memory_usage.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deploy
spec:
selector:
matchLabels:
app: my-app
replicas: 3
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
cpu: 2
memory: 100Mi
limits:
cpu: 2
memory: 100Mi파일을 만들고 실행한 후 top으로 확인해보자
위의 파일에서 request 보다 더 많은 리소스를 사용할 수 있도록 허용하고
limit은 limit 보다 더 많은 리소스를 사용할 수는 없다.
kubectl apply -f 01-deploy-cpu-memory_usage.yaml
kubectl top pods
# 15초 간격으로 확인하기 때문에 pod를 실행하고 조금 기다린 후 다시 실행하자
error: metrics not available yet
kubectl top pods
# 결과
NAME CPU(cores) MEMORY(bytes)
my-deploy-6bcdc9d88f-chvvm 0m 15Mi
my-deploy-6bcdc9d88f-hwvw8 0m 15Mi
my-deploy-6bcdc9d88f-xsdh4 0m 15Mi아래 파일처럼 CPU 수를 늘리고 replicaSet도 늘려서 적용해보자
이 숫자는 worker CPU에 따라서 변경이 가능하다
아래 예시는 CPU가 부족할때를 보기 위함이다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deploy
spec:
selector:
matchLabels:
app: my-app
replicas: 5
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
cpu: 10
memory: 100Mi
limits:
cpu: 10
memory: 100Mi확인해보면 일부 pod가 pending 상태인걸 확인할 수 있다.
describe로 확인해보자
kubectl describe pod/my-deploy-6598fd5d9-q5frf
# 결과
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 111s (x4 over 2m1s) default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }, 2 Insufficient cpu. preemption: 0/3 nodes are available: 1 Preemption is not helpful for scheduling, 2 No preemption victims found for incoming pod.pod에 CPU를 할당해야하지만 모든 CPU가 사용중이라서 불가능하다.
해결방법은 실제로 노드를 늘리거나 pod를 줄이는 방법이다.
HPA template
2개의 파일을 만들자
# 02-deploy-for-hpa.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deploy
spec:
selector:
matchLabels:
app: my-app
replicas: 1
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx
startupProbe:
httpGet:
path: /
port: 80
periodSeconds: 1
failureThreshold: 30
readinessProbe:
httpGet:
path: /
port: 80
periodSeconds: 5
failureThreshold: 3
resources:
requests:
cpu: 50m
memory: 10Mi
limits:
cpu: 50m
memory: 10Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: my-app
ports:
- port: 80
targetPort: 80
---
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
spec:
terminationGracePeriodSeconds: 1
containers:
- name: demo
image: vinsdocker/util
args:
- "sleep"
- "3600"위의 파일은 deployment와 데모를 위한 pod 그리고 외부 접속을 위한 service이다.
nginx version에 따라서 cpu나 memory가 더 필요하면 pod가 켜지지 않을 수도 있다. 적당히 조절해주자
# 03-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deploy
minReplicas: 1
maxReplicas: 3
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 10
behavior:
scaleDown:
stabilizationWindowSeconds: 10이 파일은 deployment를 감시하며 autoscaling을 할 HPA 파일이다
이제 적용해보자
kubectl apply -f 02-deploy-for-hpa.yaml
kubectl apply -f 03-hpa.yaml이제 demo pod로 접속한 후 부하 테스트를 진행해서 pod가 auto scaling이 되는지 확인해보자
kubectl exec -it demo-pod -- bash
root@demo-pod:/# ab -n 20000 -c 5 http://nginx/그러면 CPU가 더 사용됨에 따라 auto scaling이 되는것을 확인할 수 있다.
이 후 작업이 완료되면 다시 1개로 돌아온다
HPA - Without Probe
이전 2번에서 probe를 주석 처리 하자
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deploy
spec:
selector:
matchLabels:
app: my-app
replicas: 1
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx
# startupProbe:
# httpGet:
# path: /
# port: 80
# periodSeconds: 1
# failureThreshold: 30
# readinessProbe:
# httpGet:
# path: /
# port: 80
# periodSeconds: 5
# failureThreshold: 3
resources:
requests:
cpu: 50m
memory: 20Mi
limits:
cpu: 50m
memory: 20Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: my-app
ports:
- port: 80
targetPort: 80
---
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
spec:
terminationGracePeriodSeconds: 1
containers:
- name: demo
image: vinsdocker/util
args:
- "sleep"
- "3600"이제 적용해보자
kubectl apply -f 02-deploy-for-hpa.yaml
kubectl apply -f 03-hpa.yaml데모 파드로 접속한 후 요청을 보내보자
kubectl exec -it demo-pod -- bash
ab -n 20000 -c 5 http://nginx/중간에 connection이 거절당하는 것을 확인할 수 있다.
Benchmarking nginx (be patient)
Completed 2000 requests
Completed 4000 requests
Completed 6000 requests
Completed 8000 requests
Completed 10000 requests
Completed 12000 requests
apr_socket_recv: Connection refused (111)
Total of 12928 requests completed왜 이런일이 발생할까?
오토스케일링은 발생한다. 하지만 Probe가 있으면 컨테이너가 준비 된 후에 요청을 받지만
Probe가 없으면 컨테이너가 준비되기 전에도 요청을 받기 때문에 연결이 거부되는 상황이 생긴다.
'Kubernetes' 카테고리의 다른 글
| [Kubernetes] Ingress (0) | 2024.12.30 |
|---|---|
| [Kubernetes] Persistent Volume & StatefulSet (0) | 2024.12.30 |
| [Kubernetes] Secret (0) | 2024.12.19 |
| [Kubernetes] ConfigMap (0) | 2024.12.19 |
| [Kubernetes] Probes (0) | 2024.12.19 |